论文背景
标题: A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive
一种大模型响应采样理论:部分描述性和部分规范性
机构:CISPA亥姆霍兹信息安全中心,TCS研究院,微软
ACL 2025最佳论文
定义
首先弄明白标题里说的Descriptive和Prescriptive是什么。
论文附录的定义是这样写的。
描述性成分(Descriptive component):描述性是指观察到的模式,这些模式定义了给定概念中典型的或统计上频繁的内容。在LLM中,它对应于从每个概念的预训练数据中学习的底层统计概率分布,反映了常见的词序列和结构。
规范性成分(Prescriptive component):概念的规范性反映了认知主体或模型中编码概念的隐含理想或规范标准。在人类认知中,它反映了概念的价值,可以表现为决策中的道德、文化或目标导向偏见。在LLM中,规范性成分似乎来自训练数据和RLHF的模式,影响输出以符合隐含的“理想”概念,而不仅仅是统计规范。LLM中的“理想”概念不必与人类价值观保持一致。
摘要
大型语言模型(LLMs)在自主决策中应用日益广泛,它们从庞大的动作空间中采样选项。然而,指导这一采样过程的启发式方法仍缺乏深入研究。本文研究了这种采样行为,并表明其底层启发式方法类似于人类决策:包含一个描述性成分(反映统计规范)和一个规范性成分(LLM中编码的概念隐含理想)。我们证明,样本偏离统计规范朝向规范性成分的现象在公共卫生、经济趋势等不同现实领域中的概念中始终出现。为进一步说明该理论,本文展示了LLM中的概念原型受规范性规范影响,类似于人类中的常态概念。通过案例研究和与人类研究的比较,本文说明在现实应用中,LLM输出中样本向理想值转变会导致显著偏倚的决策,引发伦理问题。
引言
决策制定是一项具有挑战性的任务,通常需要从庞大的可能性集合中选择一个选项。在许多现实世界中,由于需要权衡这些数不胜数的选项来决定行动,这个过程在计算上是不可行的,因此,智能体采用启发式方法来采样它们的选项。例如,研究表明人类(和动物)通常只权衡少数选项,这些选项是基于由可能性(一个选项的统计可能性)和效用(与选项相关的价值)引导的启发式方法来选择的。尽管LLMs通常被描述为“系统-1”(System-1)智能体,其特点是依赖启发式方法,但控制它们响应采样的机制仍缺乏深入研究。
系统1即快思考,thinking。
系统2即慢思考,reasoning。
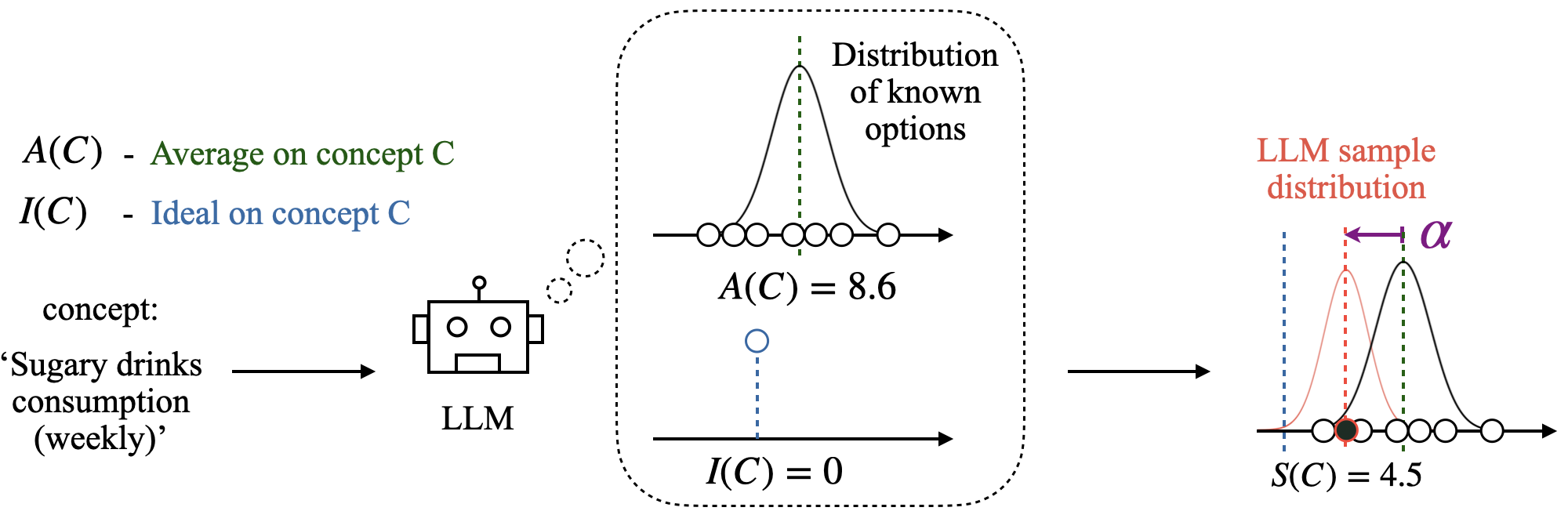
从左到右:当对一个概念进行采样时,LLM似乎考虑了该概念的统计可能性(A(C))和规范性规范(I(C))。因此,样本分布表现出向理想方向(最右侧图)偏移(以α表示),远离真实分布。
本文设计了一个关键实验来分离出所提出理论的效应。然后展示了这种启发式方法在不同现实世界领域中持续出现的效果。本文进行了涵盖不同LLMs、评估概念和消融实验的广泛实验,以展示观察结果的鲁棒性。本文展示了一个医疗案例研究,其中将LLM作为代理用于为患者分配恢复时间,以展示潜在的实践问题。如图1所示,所提出的理论表明,当LLM为某个概念挑选样本时,样本不仅反映了该概念的统计规律性(描述性规范),而且还系统地融入了该概念的理想化版本(规范性规范)。这些转变可能与人类理想不一致,当LLMs用于自主决策时,会引发伦理问题。
贡献点
- 通过人类认知研究的角度来研究LLMs中的采样机制。本文表明,驱动人类和LLMs采样过程的自助规则都包含描述性成分和规范性成分。构建了一个实验环境来隔离效应,并通过许多鲁棒性检验和与人类研究的比较来实证验证所提出的理论。
- 评估了10个领域中500个现有概念的样本,以验证所提出的理论的有效性。在涵盖不同系列和规模的15个语言模型上发现结果具有统计学意义。展示了一个受现实应用启发的案例研究,其中这一规定性部分可能导致不期望的结果。
- 证明LLMs对概念的原型表示系统地包含了规定性规范,显示出初步证据表明它们对“典型”示例的判断倾向于理想化的版本,类似于人类的原型概念。
现有问题
近期研究表明,尽管LLM agent理解概率的概念,但在概率采样方面存在困难。它们未能充分表征统计信息,即不擅长生成与预期概率模式相符的样本。本文提供了一个系统框架,解释了LLMs样本中的组成部分。这有可能解释LLMs表现出的不同偏差。
以往的研究主要使用抽样方法来处理行动生成和决策等任务,而不是明确研究LLM的抽样机制。本文旨在填补这一空白,通过研究驱动LLM响应抽样的启发式方法,从而更深入地理解它们的决策过程。
实验结论
论文进行了大量实验,得出一些结论。
- 采样理论:LLM的抽样由描述性成分(概念的统计规范)和规定性成分(概念的理想概念)驱动。
- 随着模型规模的增加,规范性成分的影响似乎会变大。
- 规范性成分似乎源于预训练而非RLHF,尽管RLHF会加剧它。
- LLM的原型概念不仅受统计平均影响,还受潜在规范影响。这些发现表明,LLM对构成典型或原型例子的判断系统性地偏向理想化表征。(原型通常被理解为概念中最典型/代表性的成员。例如,“知更鸟”可能被认为是“鸟”概念的原型,因为它与大多数高频出现(统计)的鸟类有许多共同特征,并且具有飞行能力(鸟类所期望的值),使其成为“鸟”概念的原型例子。因此,“企鹅”——一种不会飞的鸟类——比“知更鸟”更不典型。典型性定义了概念的正常性,这会驱动采样。)
- 对于包含规范性和描述性统计的新虚构概念,人类和LLM都能捕捉这些规范并使用它们来采样选项。还注意到LLM似乎像人类一样,对收益和损失存在非对称处理。观察到对负值场景的欠采样程度超过对正值场景的过采样程度,这可能指向一种共同的乐观偏见。这种非对称性,即两个系统都更强烈地回避负面而非追求正面。
- 人类始终将理想概念化为对统计数据的适度改进(例如,理想的“每周含糖饮料数量”是2.41,而平均值是9.17),而LLM则经常默认采用绝对且更严格的标准(例如,含糖饮料为0,其他概念为18),这表明道德绝对主义。
医疗案例
LLM agent被赋予医生的角色,并被要求根据一系列症状决定患者的出院时间。在此,动作空间是正有理数(周数)。一旦LLM给出康复时间,我们也会从LLM处获得自我报告的平均和理想康复时间。自我报告的平均值明确指的是当被提示报告平均值时,LLM直接提供的平均数值。
实验中根据给定的四个症状列表给出输出(以周为单位)。发现当假设(并且事实上在这个例子中确实要求)LLM仅使用统计规范时,LLM显著偏离了统计规范康复时间,趋向于一种理想概念。在35个症状批次(每个包含四个症状)中,样本26次落在平均值的理想一侧——这是一个具有统计学意义的显著变化(二项式p=0.003)。
LLM 给出的理想值低于35种症状中30种的平均值。这意味着样本经常被拉低至平均值以下。这一发现表明,LLM在关于患者康复时间方面的决策受到规范性成分的干扰,这对临床决策、医院资源分配以及患者安全潜在风险具有重大影响。
结论
本文旨在更深入地理解控制LLM可能性采样过程的启发式方法。基于人类认知研究提出了一种理论,该理论解释了采样启发式方法应兼具描述性和规范性。然而,精确的规范性成分可能与人类不完全一致。研究结果为评估LLM如何在统计概率结果与理想规范之间取得平衡提供了一个基础框架,并引发了关于其底层表示的有趣问题。本文旨在通过行为类比和性能评估来建立联系,本发现可能对下游任务产生影响。