矩阵分解算法原文。
论文背景
2009年发表于IEEE旗下的Computer期刊。
谷歌学术引用数为7954(截至2020年12月7日)。
作者:Yehuda Koren, Yahoo Research
Robert Bell and Chris Volinsky, AT&T Labs—Research
DOI: 10.1109/MC.2009.263
PDF
Recommender System Stratrgies 推荐系统策略
两种策略:content filtering approach和collaborative filtering
前者需要收集外部信息,但这不容易得到。后者聚焦于用户过去的行为,相比前者精确度更高,但它有冷启动问题。相反,在冷启动问题方面,前者更优越。
协同过滤又分为neighborhood methods和latent factor models。
基于领域的策略又可分为基于用户和基于物品。
基于物品的策略基于同一个用户对相邻物品的评分对用户偏好进行评估。同一个用户给一件物品的相邻物品会打相似的评分。
基于用户的方法鉴定相似的用户,他们可以互相补充对方的评分信息。
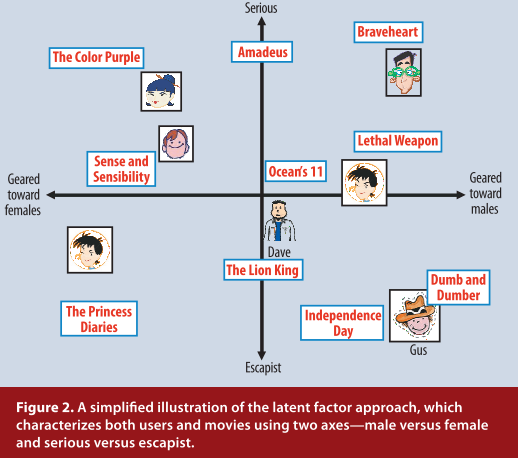
LFM隐语义模型

意思是把特征刻画分为k个维度。如图,将刻画特征设为性别和题材类别(serious/escapist),形成一个坐标空间,每个用户和物品都在这个空间中,如果在坐标系中距离越近则说明越相似。
Matrix Factorization Methods 矩阵分解策略
一些最成功的隐语义模型是基于矩阵分解实现的。
矩阵分解通过从评分矩阵推断出的因子向量来刻画物品和用户。
优势:当显式反馈无法得到时,可以添加其它信息(比如使用隐式反馈推断用户偏好)。
A Basic Matrix Factorization Model 基本矩阵分解模型
$$\hat{r}_{ui} = {q_i}^T{p_u}$$$$min_{q\*,p\*}\sum_{(u,i)∈k}({r_ui} - {p_u}^Tq_i)^2 + \lambda(||p_u||^2 + ||q_i||^2)$$其中,k是(u,i)对的集合。${r_{ui}}$是未知的(训练集)。
Learning Algorithms 学习算法
使上述式子最小化的两种方法是随机梯度下降和交替最小二乘法。
Stochastic gradient descent 随机梯度下降
$$\begin{equation}{e_{ui}}\overset{def}{=} {r_{ui}} - {q_i}^T{p_u}\end{equation}$$$${q_i} \leftarrow q_i + \gamma·({e_ui}·{p_u} - \lambda · {q_i})$$$${p_u} \leftarrow p_u + \gamma·({e_ui}·{q_i} - \lambda · {p_u})$$该方法运行速度较快。不过在有些场景下,使用ALS优化更好。
Alternating least squares 交替最小二乘法
一般随机梯度下降比ALS简单且快。但ALS适用于两个场景,一是系统可以并行化。ALS可独立计算${q_i}$和${p_u}$。二是隐式数据情况下使用。
Adding Biases
$${b_{ui}} = μ + {b_i} + {b_u}$$$$\hat{r}_{ui} = μ + {b_i} + {b_u} + {q_i}^T{p_u}$$$$min_{p\*,q\*,b\*}\sum_{(u,i)∈k}({r_ui} - μ - {b_u}- {b_i}-{p_u}^Tq_i)^2 + \lambda(||p_u||^2 + ||q_i||^2 + b_u^2 + b_i^2)$$Additional Input Sources 额外输入资源
$$\hat{r}_{ui} = μ + {b_i} + {b_u} + {q_i}^T[{p_u} + |N(u)|^{-0.5} \sum_{i∈N(u)}{x_i} + \sum_{a∈A(u)}{y_a}]$$
N(u)指用户u有过隐式反馈的若干个item集合。x是和item i相关的因素。$\sum_{i∈N(u)}{x_i}$表示一个用户对N(u)中的若干item的偏好刻画向量。系数代表规范化。
用户属性用A(u)表示,每一个用户的每一个属性对应的因素向量用$y_a$表示。$\sum_{a∈A(u)}{y_a}表示每个用户的属性集。
Temporal dynamics 时空动态
$$\hat{r}_{ui}(t) = μ + b_i(t) + b_u(t) + q_i^Tp_u(t)$$$b_i(t)$表示物品随时间变化的流行程度,$b_u(t)$表示用户评分随时间变化的严格程度,$p_u(t)$表示用户偏好随时间变化的改变程度。物品是静态的,所以$q_i$也是静态的。
Inputs with varying confidence levels 各种信任级别的输入
$$min_{p\*,q\*,b\*}\sum_{(u,i)∈k}c_{ui}({r_ui} - μ - {b_u}- {b_i}-{p_u}^Tq_i)^2 + \lambda(||p_u||^2 + ||q_i||^2 + b_u^2 + b_i^2)$$$c_{ui}$为评分的信任程度。
Netflix prize competition Netflix大奖竞赛
使用矩阵分解的方法取得了第一名的成绩。
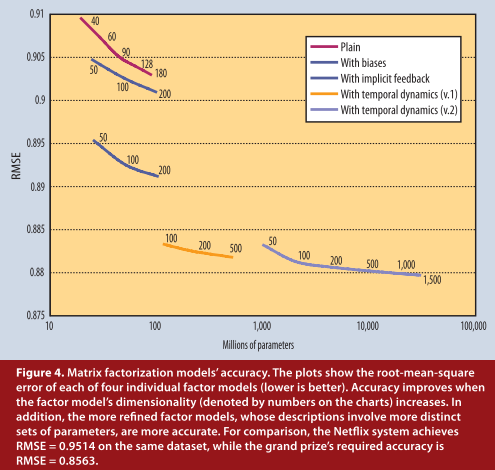 加的因素越多,精确度越高。
加的因素越多,精确度越高。
阅后总结
本文主要介绍了矩阵分解的具体算法。