推荐系统 + 深度学习 1
论文背景
WWW'15
作者:Suvash Sedhain, Aditya Krishna Menon, Scott Patrick Sanner, Lexing Xie
谷歌学术引用次数580(截至2021年2月4日)
关键词:Recommender Systems; Collaborative Filtering; Autoencoders
INTRODUCTION 引言
本文提出一种新的基于自动编码器范例的CF模型,思路来自于针对视觉和语音任务的深度神经网络模型。
和CF相比,具有表示和计算的优越性。
THE AUTOREC MODEL 模型
$$min_{\theta}\sum_{r∈S}||r - h(r;\theta)||^2_2$$$$h(r;\theta) = f(W · g(Vr + μ) + b)$$
f、g是激活函数。$\theta = {W, V, μ, b}$
$W∈\mathbb{R}^{d×k}$, $V∈\mathbb{R}^{k×d}$, $μ∈\mathbb{R}^k$, $b∈\mathbb{R}^d$
该目标对应于具有单个k维隐藏层的自连接神经网络。使用反向传播来学习参数θ。
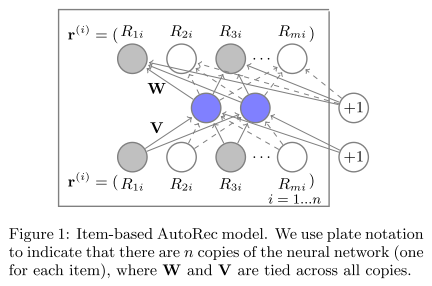
基于物品的AutoRec模型I-AutoRec
${r^{(i)}}^n_{i=1}$
 两点改变:
两点改变:
- 每个$r^{(i)}$通过反向传播更新和输入有关的权重得到,这在矩阵分解和RBM策略中常用。
- 设计了学习参数正则化防止过拟合。
$||||^2_o$代表只考虑可观测评分的贡献。
基于用户的AutoRec模型U-AutoRec
${r^{(u)}}^m_{u=1}$
和CF策略的区别:
对比基于RBM的CF模型(RBM-CF)
- RBM-CF是基于限制玻尔兹曼机的生成概率模型,AutoRec是一个基于自动编码器的判别模型。
- RBM-CF通过最大化似然log函数估计参数,AutoRec直接最小化RMSE。
- 训练RBM-CF需要使用对比散度,训练AutoRec需要相对更快的基于梯度的反向传播。
- RBM-CF只使用于离散评分,并对每个评分估计一个分散的参数集。对r个可能的评分,它使用了基于RBM的nkr或者mkr个参数用于用户(物品)。AutoRec与r无关,因此需要较少的参数。 较少的参数使AutoRec的内存占用量更少,更不容易过度拟合。
对比矩阵分解(MF)
MF学习线性潜在表示,AutoRec可以通过激活函数学习非线性潜在表示。
EXPERIMENTAL EVALUATION 实验评估
基线:RBM-CF, BiasedMF, LLORMA.
数据集:Movielens 1M, 10M 和Nerflix数据集
没有训练数据的测试集默认评分为3。
训练集:测试集=9:1
将训练集10%作为验证集。
重复划分步骤5次并记录平均RMSE。
每次实验95%在RMSE偶然的间隔在±0.003之间。
正则化参数λ∈{0.001, 0.01, 0.1, 1, 100, 1000}
潜在维度k∈{10, 20, 40, 80, 100, 200, 300, 400, 500}
三种实验
- 和RBM对比
- 激活函数选取对比
- 隐藏单元k的数量

- 基线性能对比

- 深度扩展对Auto的帮助
代码
https://github.com/mesuvash/NNRec
总结
AutoRec是最简单的深度学习推荐系统。
它是一种单隐层神经网络推荐模型,将自动编码器与协同过滤相结合。