论文背景
标题: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
原生稀疏注意力:一种硬件对齐和原生可训练的稀疏注意力
机构:DeepSeek、北大、华盛顿大学
论文地址:https://arxiv.org/abs/2502.11089
ACL 2025最佳论文
现有问题
- 阶段限制
现有大多数现代稀疏注意力方法主要在推理过程中使用,预训练/预填充阶段依然保留全注意力(例如注意力图计算、索引构建),比如H20算法。而MInference算法只关注预填充阶段的稀疏性,又无法在推理阶段实现加速。所以至少有一个阶段的计算成本仍与全注意力相当。 - 与高级注意力架构不兼容
一些稀疏注意力方法无法适应现代高效解码架构,如多查询注意力(MQA)和分组查询注意力(GQA),他们在多个查询头间共享KV,显著减少了解码过程中的内存访问瓶颈。(例如,Quest算法中,每个注意力头独立选择其KV缓存子集。)虽然这些稀疏注意力算法可以减少计算,但它们分散的内存访问模式与先进架构的高效内存访问设计相冲突。现有的稀疏注意力方法专注于KV缓存减少或理论计算减少,但在高级框架难以实现显著的延迟减少。
几个动机: - 性能下降
事后应用稀疏性迫使模型偏离其预训练的优化轨迹。前20%的注意力只能覆盖总注意力分数的70%,这使得预训练模型中的检索头等结构在推理过程中容易被裁剪。 - 训练效率需求
现有稀疏注意力方法主要针对推理,训练中的计算挑战在很大程度上没有得到解决。这种限制阻碍了通过高效训练开发更强大的长上下文模型。 - 不可训练的组件
ClusterKV等方法中的离散运算和MagicPIG算法在计算图中产生不连续性,这些不可训练的组件阻止了token选择过程中的梯度流动,限制了模型学习最佳稀疏模式的能力。 - 反向传播效率低下
一些理论上可训练的稀疏注意力方法实际训练时效率低下。比如HashAttention算法,使用token粒度筛选策略导致需要在注意力计算期间从KV缓存加载大量单个标记。这种非连续的内存访问阻碍了快速注意力技术(如FlashAttention)的有效适应,它依赖于连续内存访问和分块计算来实现高吞吐量。结果,被迫退回到低硬件利用率,从而显著降低训练效率。
为此,提出了NSA,这是一个原生稀疏注意力框架,可以同时满足计算效率和训练要求。
NSA
背景
- 随着序列长度增加,注意力计算在总体计算成本中变得越来越主导
- 算术强度(Arithmetic Intensity)
算术强度=计算操作数/内存访问数。它从本质上塑造了硬件上的算法优化。每个GPU都有一个临界算术强度,由其峰值计算能力和内存带宽决定。对于计算任务,高于此临界阈值的算术强度将成为计算受限(受GPU FLOPS限制),而低于该阈值则成为内存受限(受内存带宽限制)。
具体到因果自注意力机制,在训练和预填充阶段,批量矩阵乘法和注意力计算表现出较高的算术强度,使得这些阶段在现代加速器上具有计算约束。相比之下,自回归解码变得内存带宽受限,因为它每次前向传递生成一个令牌,同时需要加载整个键值缓存,从而导致算术强度低。这导致了不同的优化目标——降低训练和预填充期间的计算成本,同时减少解码期间的内存访问。
整体框架
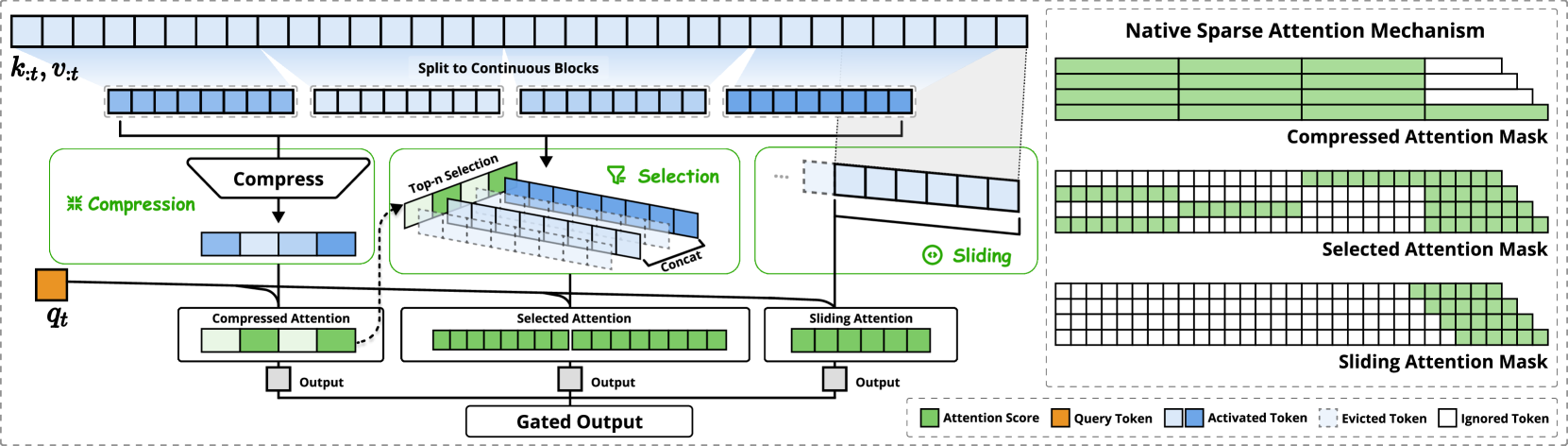
左图:框架通过三个并行注意力分支处理输入序列:对于给定的查询,前面的键和值被处理为粗粒度模式的压缩注意力,重要标记块的选择注意力,以及本地上下文的滑动注意力。右图:每个分支产生的不同注意力模式的可视化。绿色区域表示需要计算注意力分数的区域,而白色区域表示可以跳过的区域。
通过确保$N_t≪t$来保持高稀疏率。
每一种映射策略具体的算法设计请看原论文,因为我目前暂未研究该方向所以未精读。
内核设计
为了在训练和预填充过程中实现FlashAttention级别的加速,在Triton上实现了硬件对齐的稀疏注意力内核。鉴于MHA是内存密集型且解码效率低下的,本文专注于具有共享KV缓存的架构,如GQA和MQA,遵循当前最先进的LLM。虽然压缩和滑动窗口注意力计算很容易与现有的 FlashAttention-2内核兼容,但本文引入了稀疏选择注意力的专用内核设计。如果遵循FlashAttention 将时间连续查询块加载到SRAM中的策略,这将导致内存访问效率低下,因为块内的查询可能需要不相交的KV块。为了解决这个问题,关键优化在于不同的查询分组策略:对于查询序列上的每个位置,将GQA组中的所有查询头(它们共享相同的稀疏KV块)加载到SRAM中。 如图,说明了前向传递实现。
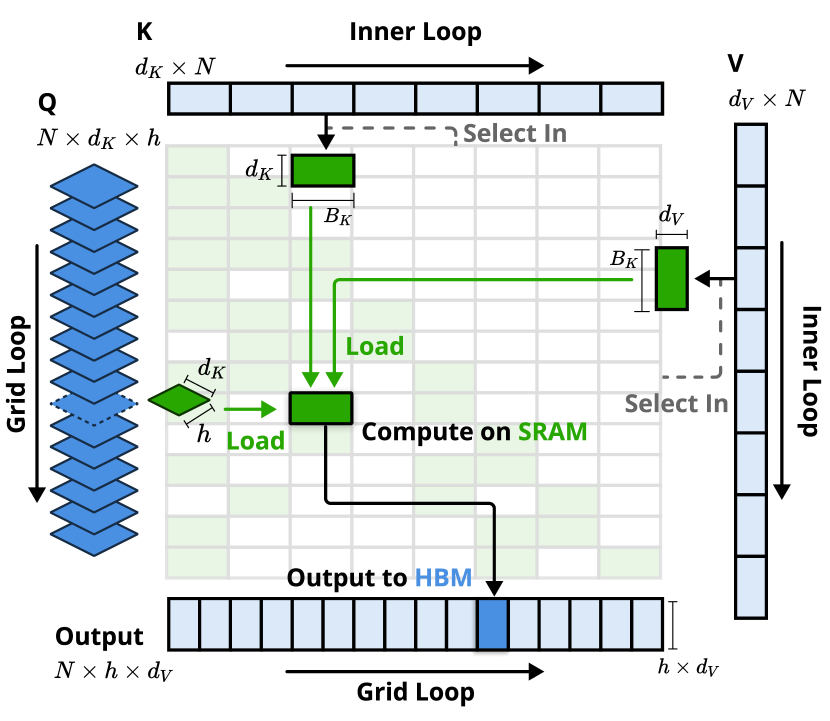
内核按GQA组加载查询(Grid Loop),获取相应的稀疏KV块(Inner Loop),并在SRAM上进行注意力计算。绿色块表示SRAM上的数据,而蓝色块表示HBM上的数据。
性能
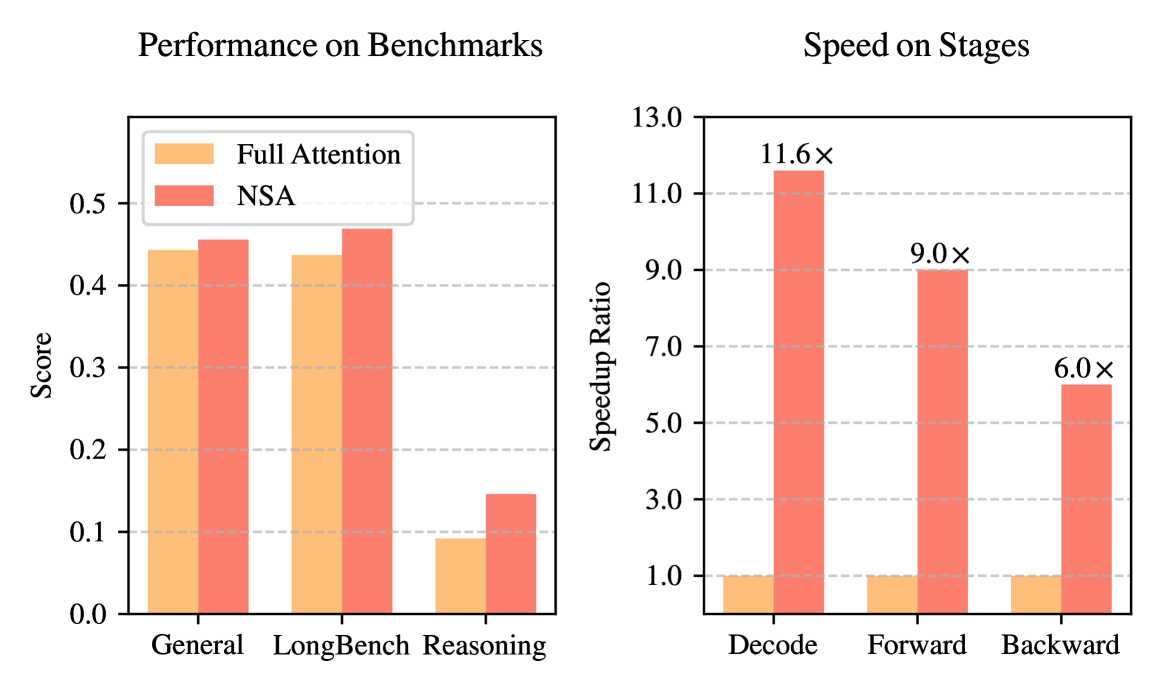
左图:在一般、长上下文和推理任务中都比全注意力好。右图:在解码、前向传播和后向传播上都提速明显。
总结
本文提出了NSA,这是一种硬件对齐的稀疏注意力架构,用于高效的长上下文建模。通过在可训练架构中将分层token压缩与分块token选择集成在一起,架构实现了加速训练和推理,同时保持了全注意力性能。