DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: 通过强化学习激励LLMs中的推理能力
DeepSeek 2025
摘要
本文介绍了我们第一代生成式推理模型,DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero是一个无需微调(SFT)作为初始步骤,只通过大规模强化学习(RL)来训练的模型,它展现出强大的推理能力。通过强化学习,DeepSeek-R1-Zero自然涌现出巨大能力和推理行为。然而,它存在可读性差和语言混淆的问题。为了解决这些问题并加强推理性能,我们提出DeepSeek-R1,它在强化学习前融合了多阶段训练和冷启动数据。DeepSeek-R1在推理任务上和OpenAI-o1-1217性能相当。
这两个模型已开源,并给出了从Qwen和Llama得到的6种尺寸蒸馏版本(1.5B、7B、8B、14B、32B、70B)。
开源地址:https://github.com/deepseek-ai/DeepSeek-R1
引言
贡献点:
- 后训练:在基座模型上大规模强化学习
我们将RL直接用于基座模型,不用SFT,得到DeepSeek-R1-Zero。
引入了一种基线操作得到DeepSeek-R1。它包括两个强化学习阶段,用于发现增强推理模式并对齐人类偏好,同时有两阶段SFT,用来初始化模型推理以及获取非推理能力。 - 蒸馏:小模型也可以有很强的性能
方法
DeepSeek-R1-Zero:在基座模型上强化学习
强化学习算法
GRPO(组相对策略优化)
为了节省强化学习的训练费用,我们采用了GRPO(Group Relative Policy Optimization)。它放弃了通常与策略模型大小相同的critic模型,而是从各组分数中估计基线。
对于每个问题q,GRPO从老策略$π_{θ_old}$中采样一组输出${o_1, o_2, …, o_G}$,然后通过最大化下列目标来优化该策略模型$π_θ$:
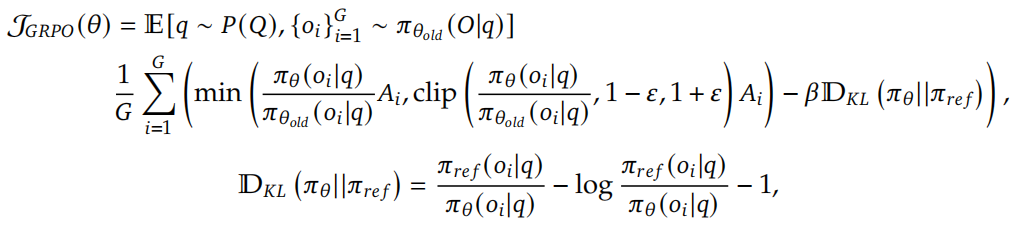
奖励模型
奖励是训练信号的来源,它决定了RL的优化方向。
为了训练DeepSeek-R1-Zero,我们采用了一个基于规则的奖励系统,主要由两种类型的奖励组成:
- 准确性奖励(Accuracy rewards) 用于评价回复是否正确。例如,对于具有确定性结果的数学问题,模型需要以指定的格式(例如,在一个方框内)提供最终答案,从而实现可靠的基于规则的正确性验证。类似地,对于LeetCode问题,可以使用编译器来基于预定义的测试用例生成反馈。
- 格式奖励(Format rewards)
除了准确性奖励模型外,我们还采用了一种格式奖励模型,强制该模型将其思维过程置于
<trink/>和</trink>标签之间。 在训练DeepSeek-R1-Zero时,我们没有使用ORM或PRM模型,因为我们发现奖励模型在大规模强化学习过程中会出现reward hacking,并且它需要额外训练资源,会增加训练流程的复杂度。
训练模板
|
|
prompt在训练时会被替换为特定的推理问题。
这个模板首先产生一个推理过程,然后是最终的答案。
我们的限制仅限于此,避免了特定内容偏差,让模型自然推理。
性能、自我演化过程和顿悟时刻
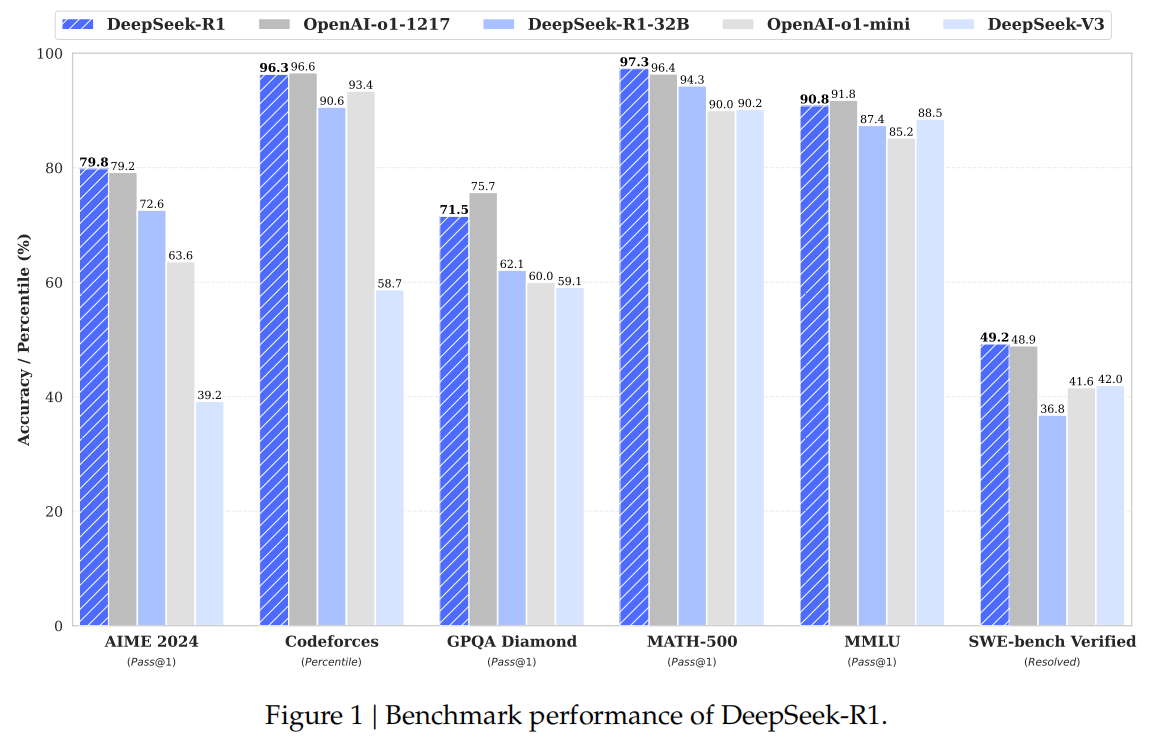
性能:
(这个顿悟时刻写的是aha moment就很啊哈……)
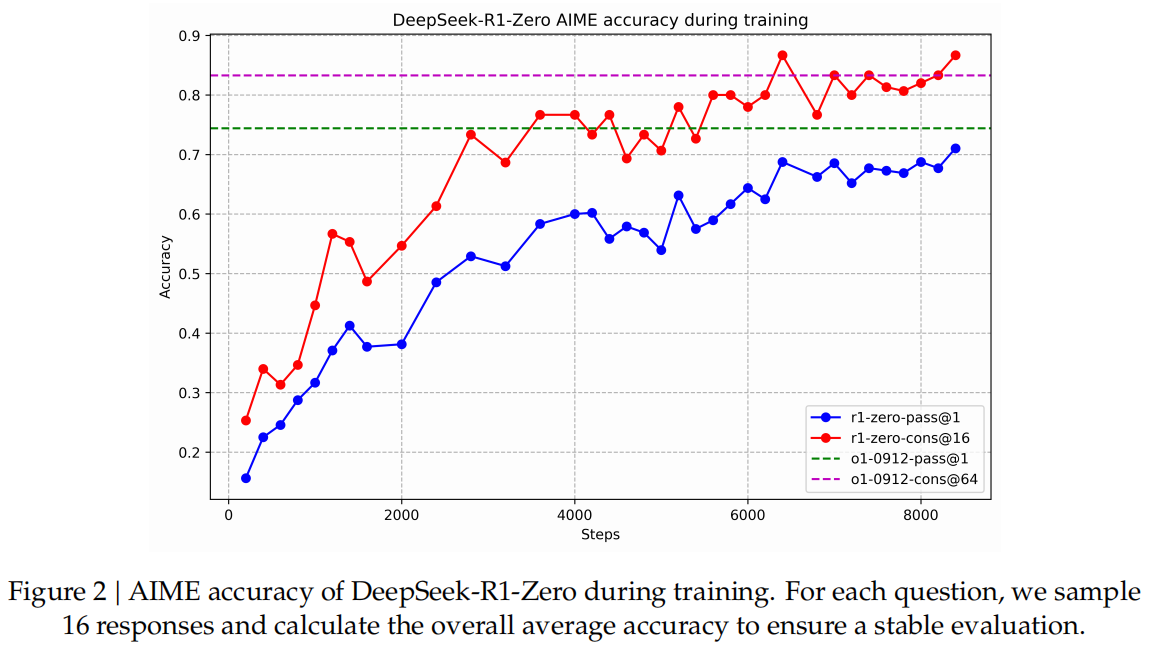 自我演化过程:
自我演化过程:
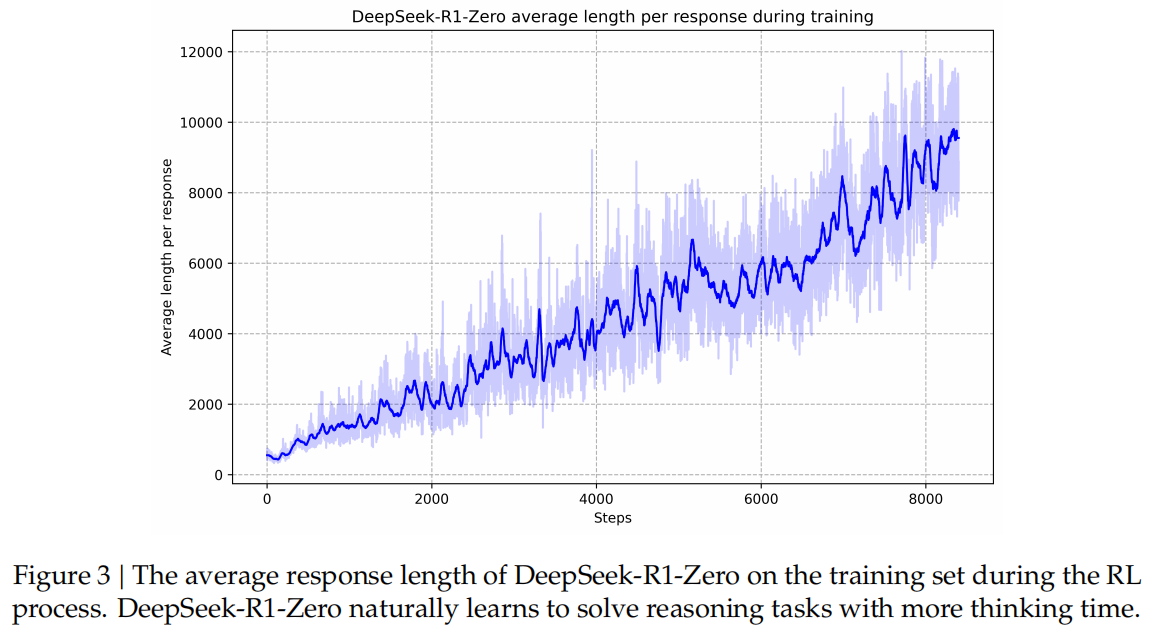 推理时间增加(平均每个token回复的时长),推理能力也增强。
推理时间增加(平均每个token回复的时长),推理能力也增强。
其中最显著的是随着测试时间增加,复杂行为的涌现(比如反省)。这个行为是自然而然产生的,而不是显式编码导致的。
顿悟时刻:
模型在中间版本突然产生了顿悟。模型学会分配更多的思考时间去重新评估初始策略。
它强调了强化学习的力量和美:我们不是明确地教授模型如何解决问题,而只是为它提供正确的激励,它自主地开发先进的问题解决策略。
 缺点:
缺点:
可读性差、语言混淆
为了解决这些问题,提出了DeepSeek-R1。
DeepSeek-R1:使用冷启动数据强化学习
两个问题:
1)推理能力是否可以用少量高质量数据作为冷启动来提升性能和加速收敛?
2)是否能训练一个用户友好的模型,不仅产生清晰易懂的思维链,也能具备通用能力?
为此提出DeepSeek-R1的基线流程,包括四步。
冷启动
我们构建了少量长思维链数据来微调模型作为初始RL的actor。为了收集这些数据,采用了几种方法:使用长思维链带few-shot的指令直接让DeepSeek-R1-Zero生成带反思的详细答案(可读的格式),然后经过人类标注员的复核。
这些冷启动数据微调DeepSeek-V3-Base模型,作为RL的起始点。
冷启动数据的优点:
- 可读性
定义了一种输出格式:|special_token|<reasoning_process>|special_token|<summary>增强可读性。 - 潜力
性能相比DeepSeek-R1-Zero性能更好。
基于推理的强化学习
用冷启动数据微调DeepSeek-V3-Base后,进行和DeepSeek-R1-Zero一样的大规模强化学习过程。
训练过程中,我们观察到思维链经常展现语言混淆,尤其是强化学习指令中涉及多语言时。为了缓解语言混淆的问题,我们在RL训练中引入了一种语言一致性奖励,即在思维链中计算目标语言词汇的比例。虽然消融实验显示这个对齐结果会轻微降低模型性能,但是它对齐了人类偏好,使其更可读。因此,我们将推理任务的准确性和语言一致性的奖励直接相加在一起作为最终的奖励。
拒绝采样和SFT
RL收敛后,使用该checkpoint来收集SFT数据用于接下来的训练。不像初始的冷启动数据(主要聚焦推理能力),这一阶段主要融合非推理数据(写作、角色扮演和其它一般性任务)。生成数据和微调模型和前面一样。
推理数据:我们通过从上述RL训练的checkpoint进行拒绝采样来管理推理提示并生成推理轨迹。在前一个阶段,我们只使用了能被基于规则的奖励评估的数据。然而,在这一阶段,我们通过合并额外的数据来扩展数据集,其中一些数据使用生成式奖励模型,这些数据通过将标签和模型预测输入到DeepSeek-V3中进行判断来生成。模型输出有时可读性差,所以过滤掉了语言混淆的思维链、长段落和代码块。对于每个指令,采样了多种回复并只保留了正确的一个回复。我们搜集了总计大约600k推理相关的训练样本。
非推理数据:采用了DeepSeek-V3的流程,复用了V3的SFT数据。对于某些非推理任务,我们调用DeepSeek-V3,在通过提示回答问题之前生成一个潜在的思维链。不过,对于简单问题,比如“hello”,不提供思维链回复。最终,我们收集了大约200k非推理的训练样本。
我们使用上述800k样本微调了两轮DeepSeek-V3-Base。
全场景强化学习
为了进一步使模型与人类的偏好保持一致,我们进行了第二次强化学习,旨在提高模型的帮助性和无害性,同时改进其推理能力。具体来说,我们使用奖励信号和不同的提示分布的组合来训练这个模型。对于推理数据,我们坚持DeepSeek-R1-Zero中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般的数据,我们诉诸于奖励模型来捕捉人类在复杂和微妙的场景中的偏好。我们以DeepSeek-V3基线流程基础,采用了类似的偏好对分布和训练提示。对于帮助性,我们只关注最终的总结,确保评估强调对用户回复的效用和相关性,同时最大限度地减少对底层推理过程的干扰。对于无害性,我们评估模型的整个回复,包括推理过程和总结,以识别和减轻在生成过程中可能出现的任何潜在风险、偏见或有害内容。最终,奖励信号和不同的数据分布的整合使我们能够训练出一个擅长推理的模型,同时优先考虑帮助性和无害性。
蒸馏小模型
我们使用800k样本在Qwen和Llama上进行了微调。结果表明,这种简单的蒸馏方法显著提高了较小模型的推理能力。
对于蒸馏的模型,我们只使用了SFT,没有使用RL。
讨论
蒸馏 vs 强化学习
结论:
- 在小模型上,蒸馏有用,用强化学习需要很大算力且不一定能达到蒸馏效果。
- 虽然蒸馏经济实惠,但是要突破智能边界还是需要更强大的基座模型和大规模强化学习。
失败的尝试
- 过程奖励模型(PRM)
三大限制:
- 对于一般推理难以定义细致步骤。
- 当下步骤是否正确难以判断。
使用模型自动标注可能无法产生令人满意的结果,而手动标注则不利于扩展。 - PRM必然导致reward hacking,再训该奖励模型需要另外的训练资源,使训练过程复杂化。
总之,虽然PRM显示了一种不错的能力来重新排序guided seearch中模型生成的top-N回复,但与我们实验大规模强化学习过程中引入的额外计算开销相比,它的优势是有限的。
- 蒙特卡洛树搜索(MCTS)
这种方法涉及到将答案分解成更小的部分,以允许模型系统地探索解决方案空间。为了促进这一点,我们提示模型生成多个对应于搜索所需的特定推理步骤的多个标签。在训练中,我们首先使用收集到的指令,通过预先训练的价值模型引导的MCTS找到答案。随后,我们使用所得到的问答对来训练actor模型和value模型,迭代地细化过程。
遇到的问题:
- 不像国际象棋搜索空间是定义好的,这里的搜索空间呈指数型增加。为了解决这个问题,我们为每个节点设置了一个最大的扩展限制,但是这会导致模型陷入局部最优解。
- 训练一个高质量value模型是很难的。而它直接影响搜索过程每一步生成的质量。由于token生成的复杂性,在AlphaGo中的成功无法直接复制到我们的实验中。
综上所述,虽然MCTS在与预先训练过的价值模型配对可以提高推理过程中的性能,但通过自搜索迭代提高模型性能仍然是一个重大挑战。
展望
- 一般能力
DeepSeek-R1在一般能力(函数调用、多轮、复杂角色扮演、JSON输出)上比DeppSeek-V3差。我们计划探索长思维链如何增强这些领域的能力。 - 语言混淆
DeepSeek-R1现在是用中文和英语优化的,当处理其它语言时会出现语言混淆问题。比如,当问题是其它语言时,模型仍会使用英语作为推理和回复。 - 提示工程
Few-shot会降低模型性能。我们推荐用户直接使用zero-shot来问问题。 - 软件工程任务
大规模强化学习还没扩展到软件工程任务。在这方面DeepSeek-R1相比DeepSeek-V3没有大的提升。未来的版本将通过对软件工程数据采取拒绝抽样或在RL过程中合并异步评估提高效率来解决这个问题。